A startup exercise in building a caring, insightful, and funny matchmaking bot
During the Miami Hack Week I went to a side event (a chess tournament hosted by Mantle). There were two dogs at the event and while playing with them another attendee chatted to me about his pet image app. He then told me that he’s also thinking of building a matchmaking bot using AI. I had an idea about recommender systems and next day we met at one of the hacking houses, the excellent social house.
I. Language Models
I was worried that I’d have to build a recommendation system from scratch, but luckily AI pretty much built it itself! Meaning, we used a similarity search method to find two “similar” people (on similarity vs compatibility - another time). Let’s unpack: similarity is some measure of distance between things and similarity search generally allows searching where the only available comparator is the similarity between any pair of objects with no natural order, like in words. Further, semantic search understands contextual similarities between texts (even if they don’t have the same words), a considerable upgrade from the alternative method, the keyword or, lexical search.
What makes semantic search possible is taking a word and putting it into numbers, a method called vectorization, where a vector represents the occurrence or absence of specific words or features in the text. Text on a coordinate plane means similar words are close by and different words are far away. This allows us to use things like the parallelogram rule (ie Zagreb to Rabat is what Croatia is to Morocco) and basic arithmetic (as well as nearest neighbors) to solve quizzes like this:
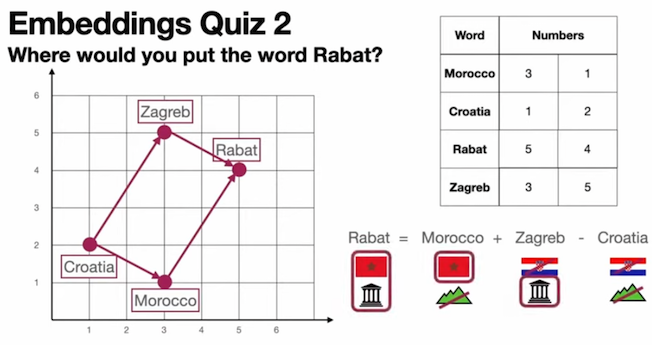
(source: Luis Serrano).
It’s easy to map individual words onto vectors, treating them as separate features (with methods like bag-of-words models, term frequency-inverse document frequency (TF-IDF), or one-hot encoding), but it gets harder when it comes to combining concepts into sentences or paragraphs as this approach doesn’t take into account the fact that the meaning of a word can change depending on the context in which it is used. Embeddings, on the other hand, were developed to capture the context, or the semantic relationships between words too. A “denser” type of vectorization, they are learned through the use of deep neural networks using methods like Word2Vec, or GloVe (Global Vectors for Word Representation). That makes the conversation agent contextually aware, more akin to human comprehension.
Large Language Models (LLMs) like OpenAI, Cohere, etc used word embeddings to map natural language into a high-dimensional abstract space of word vectors (~10k dimensions, while average person uses ~3-4k, source), revolutionizing the field of natural language processing by being able capture the semantic and syntactic relationships between words in a meaningful way. In addition to search, this allows us to do problems like question answering, sentiment analysis, text completion, translation, summarization and more.
The architecture of an NLP application typically includes the base layer of LLMs, and an additional computational layer where packages like Langchain and its ecosystem provide a level of abstraction of interacting with an LLM. Combining the two brings out the real power of this transformative technology because it lets you build upon the general knowledge models to adapt it to your use-case. Langchain ecosystem allows adding, managing and retrieving your own knowledge base, making sure it answers in a relevant way and definitely doesn’t hallucinate. Langchain’s main building bricks are chains: they piece together other LLM tools like chatbots, generative QA, summarization, logic loops (web search) together in a logical fashion. This allows us to execute a common external knowledge pipeline along the lines of:
- Indexing: index the data: the custom “knowledge base”, and the query, by feeding it into an embedding model that translates it into a numerical representation of the semantic meaning behind it in vector space.
- Querying: aka the retrieval component, maps the query into vector space based on its meaning to then compare it and return similar ones, answering the query based on the embedded custom knowledge.
- Generation: produces a more intelligent answer by using the custom “knowledge base” in addition to general knowledge and by “translating” the output of the vector query back to human language via text generation model.
How did we make ML-E an empathetic, insightful, curious, and fun matchmaker? We did it with a little nudging, also known as prompt engineering, which helps us get the best quality generations for the task, the outputs we intend to get. Kinda like abstract programming of an AI model, prompts fine-tune, or transform the pre-trained model by giving it info like instructions, context, and query - and save us from creating a separate specialized model.
In our case, we gave ML-E an identity and told her how to behave by setting the prompt base (ever present in each consequent interaction) to something like “ML-E is a caring matchmaker that converses with the user to get to know them with a goal of helping them find a compatible romantic partner.” We included that in the prompt parameter in the OpenAI.Completion endpoint, along with “text-davinci-003” as the model parameter.
I asked chatGPT how to write good prompts when training a conversation bot and this is what it came up with, which sounds about right:
- Be clear and specific: Your prompts should clearly state what you want the bot to learn or respond to. Vague or open-ended prompts may confuse the bot and lead to irrelevant or nonsensical responses.
- Use natural language: Write prompts in a conversational tone that reflects how people actually talk. This will help the bot understand and mimic human speech patterns.
- Incorporate context: Provide context for the bot to help it understand the conversation’s flow and purpose. This can include information about the user, their preferences, or the situation at hand.
- Include variations: Write prompts in different ways to account for different ways people might phrase their questions or responses. This will help the bot learn to recognize and respond to similar inputs in the future.
- Test and iterate: Continuously test and refine your prompts based on the bot’s responses and user feedback. Use this feedback to improve the bot’s ability to understand and respond to user input accurately and effectively.
As ML-E converses with the user, she learns the context of the user’s personal and their dating preferences. What allows the bot to have a conversation, ie keep in mind the previous context, is including all the previous chat history in each new response’s prompt, resembling the experience of the chat.openai.com. When the user is ready to match, the conversation is condensed to represent the user’s bio using OpenAI’s completion endpoint and the davinci-003 model. Each bio is embedded and added to a vector database (using Langachain’s FAISS.from_texts method with the wrapper around OpenAI embedding models). To find a match, ML-E queries the vector database of other profiles and returns the most similar one using similarity_search, which is cool but of course barely guarantees to have chemistry / compatibility.
A note on the hosting architecture: the piece that keeps it all together, and enables the interaction between the AIs and the user is Beam Cloud, one of the hackathon’s sponsor. A data ETL pipeline / API deployment tool, we used Beam for compute environment, as well as hosting the back-end logic, and communicating between front-end and database (we used supabase). Beam’s straightforward Getting Started with Langchain guide started us off on the right foot. Combined with OpenAI’s Embeddings & Completions API, LangChain, FAISS, and telegram we were able to spin up an end-to-end GPT-3 powered matching engine.
II. Company Building
At the end of the hackathon we knew we wanted to continue working on the project and build a company out of it. Having refined the product (e.g. getting rid of compulsory gayness, that is, we enabled the filtering by gender preference), we decided to fundraise. To do that we needed traction, otherwise it would have been more of a commodity than a product. This is not a trivial thing. It’s easy to develop a product that puts a couple of AI models together. It’s more difficult to get traction and validate product market fit. So there were some other things we need to do before we could fundraise confidently. I looked at some books on product & marketing* and came up with a plan along the lines of:
- product: narrow down to a target customer and their needs, and develop an MVP of habit-forming features with user-centric design that solve those needs.
- marketing: the idea is to attract a community of some (~1000) really interesting people, and giving them magical high-quality matches would spin up the network effect and grow the user base that would re-invent the game of matching.
- profit: validate the product market fit by hitting on important metrics like user engagement, retention, acquisition, feedback and revenue.
When learning about fundraising, one friend warned of expectations to return the money you raised taking over your life and advised to try hard to sustain yourself by selling something in the meantime (e.g. The Boring Company collected $10m by selling 20k of not-a-flamethrowers at $500 each). But if, friend continued, we absolutely had to raise, it’s better to concentrate on independent angels, with an operator background and without LPs, ideally. So according to that school, best way to raise is not raise. As with most things in life, FOMO is a big part of it:

A principled framework to fundraising came from Ryan Breslow’s primer on the subject that touches on every facet of the process. The main idea I got out of the book was to put in a lot of the effort in the relationship building, that is to take the time to get to know the investors BEFORE you fundraise. Establishing personal connections / getting warm intros are key, perhaps through other founders of the investor’s portfolio, or through hosting gatherings. However, once you build the momentum and announce the round, move fast. Another point not to forget is that you are also evaluating the investors, and you must do due diligence on them too. Avoid big egos, unclear investment criteria, missed deadlines. Fundraising should be one of the founder’s full time job.
On team
It was an amazing feeling when the team came together and rallied around the project. We worked until 5am on the demo day without getting tired, it brought us closer together. We were lucky to have one experienced friend helping us out at the last moment and contributing a vital piece of architecture. Another piece that got us to the finish line was our marketing teammate who remembered to look up submission details and submitted our project before the deadline. Thanks to her we also had a promotional deck to showcase the next day. As tech people hacking heads down, these things can be easily overlooked but should not be underestimated! Also, thanks the social house for providing the fun grounds to make it possible for us to finish.
In the two weeks following the hackathon, we continued working on the project, but unfortunately haven’t yet agreed how to coordinate the team and company structure. Potential investors have pointed out that structural certainty was required to move forward. Currently we are at stalemate because of this. To get past this we tried frameworks like 50 questions, aka The Founder Dating Playbook, across the rubrics like roles, corporate structure and funding, personal motivation, commitment & finances, team culture, and co-founder relationship. It also helps to come up with an itemized breakdown of everything that needs to be done for the company and divide the responsibilities accordingly. The idea is to have each founder’s strengths and weaknesses complimenting each other.
Conclusion:
I am grateful and proud to have had this experience. We built an intelligent matchmaking assistant that understands your preferences and finds you a potentional “the one” in our database!
PS As i was writing this, GPT-4 has entered the picture, which is considerably more capable than the previous GPT iterations. We have definitely entered the era where humans live side-by-side with very good LLMs.
*Books that were relevant:
- INSPIRED: How to Create Products Customers Love by Marty Cagan by Nir Eyal
- Hooked: How to Build Habit-Forming Products
- The Cold Start Problem: How to Start and Scale Network Effects by Andrew Chen
- The Lean Product Book: How to Innovate with MVPs and Rapid Customer Feedback by Dan Olsen
- Lean Analytics: Use Data to Build a Better Startup Faster by Alistair Croll & Benjamin Yoskovitz
- Creating a Data-Driven Organization: Practical Advice from the Trenches by Carl Anderson
- Books by the Product School and Intercom